Neural encoders are sophisticated neural networks that transform diverse inputs—including text, images, and audio—into dense numeric representations (embeddings) that capture essential semantic features and contextual meaning. These embeddings serve as the foundation for numerous machine learning applications by distilling complex, high-dimensional data into more manageable and meaningful vector spaces.
These powerful encoding mechanisms form the backbone of many modern AI systems, including encoder-decoder architectures that power machine translation, autoencoders that enable dimensionality reduction and generative capabilities, transformer models that have revolutionized natural language processing, and retrieval systems that power search engines and recommendation platforms. By learning to represent data in ways that preserve semantic relationships, neural encoders enable machines to process information in increasingly human-like ways.
In this blog we will cover some widely used, battle tested architectures which are most used in the industry and some latest advancements in the field.
Autoencoders
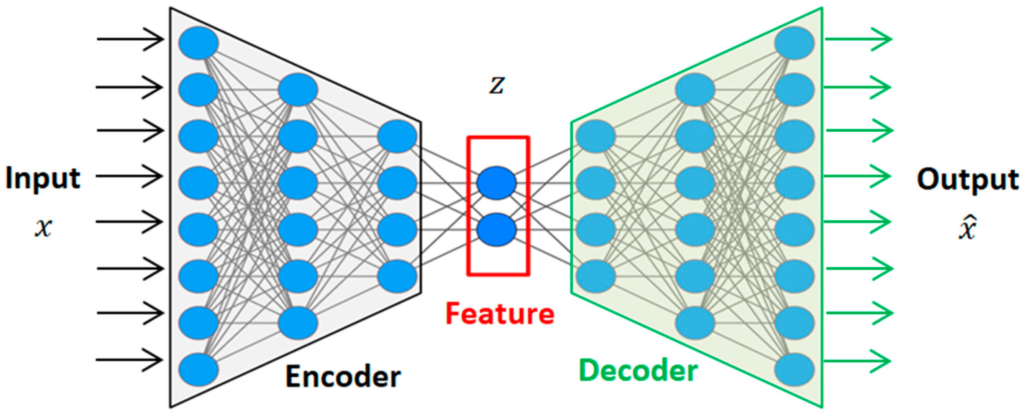
An autoencoder encodes an item (text, image, or audio) into a dense embedding, which is then used to reconstruct partial or complete parts of the input using a decoder. This process allows the encoder to extract important features from the input that are essential for decoding/generating the output. During this process, the encoder learns to encode features relevant to the output while removing information that is not required for decoding.
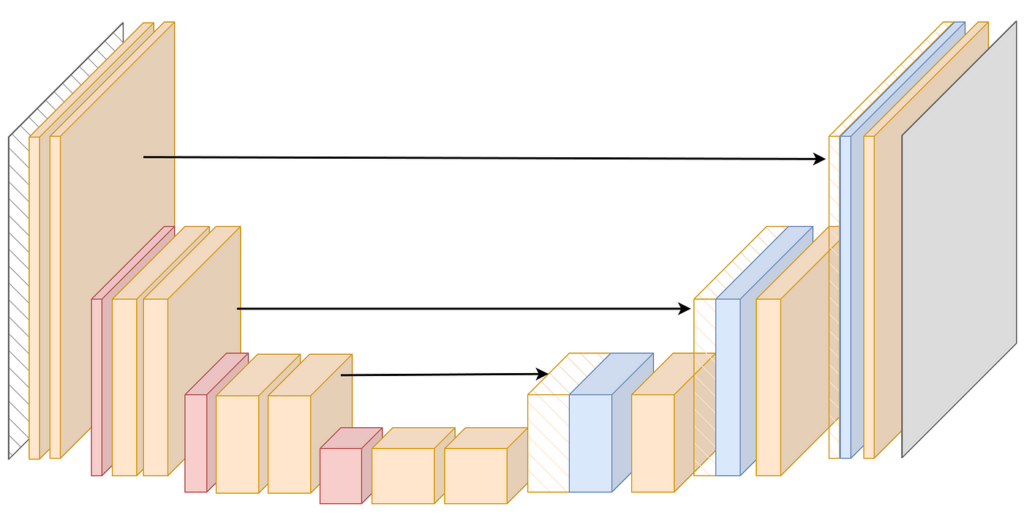
In a U-Net architecture for pose estimation, the encoder captures pose information in the embedding, which is then used to recreate the spatial pose image for the given input. Similarly, in diffusion models, the model learns to remove noise from an input to generate a slightly denoised output. In neural compression and encryption, the latent representation can be transferred over a network and be decoded by the decoder.
In autoencoders, the reconstructed output defines which information should be captured in the latent embeddings. This works using the principle of information bottleneck in neural networks. The information bottleneck principle aims to find a compressed representation of a variable (X) that preserves the most relevant information about another variable (Y) while minimizing the information about X itself.
In U-Net architecture, multiple latent information paths from the encoder are passed to the decoder using skip connections, but the underlying principle of information bottleneck still holds true.
Common Applications: Compression, denoising autoencoders, image generation, diffusion models, and U-Net architecture for feature extraction.
Dual Encoder:
Dual encoders (also known as bi-encoders) generate embeddings for two entities A and B in a common latent space. In search systems, A and B typically represent queries and items, with their respective encoders called query tower and item tower.
The latent space is defined by the nature of the task and training data. It determines which A-B, A-A, and B-B pairs should be positioned near or far from each other. For search problems, relevant items should be closer to each other compared to non-relevant items. Similarly, for recommendation problems, items which users are likely to consume should be positioned closer together. Thus, the latent space definition derives from the specific task and training data.
The dual encoder structure allows for generating embeddings for both queries and items. The query embedding is used to retrieve items that are nearest in the latent space, defined by similarity functions. Recent advances in Maximum Inner Product Search (MIPS) have increased the adoption of dual encoders in industry for retrieval problems, particularly semantic retrieval.
Why semantic retrieval? Recent advancements in Large Language Models (LLMs) and self-supervised training have given these models vast understanding of the world, enabling them to comprehend different representations of the same information and extract relevant information not possible with lexical matching.
Why only retrieval problems? Dual encoders are primarily used for retrieval problems because they enable fast searching of items. However, they cannot embed complexity and precision due to limited representation capabilities of the embedding, latent space, and similarity function. These spaces are generally Euclidean, which can only capture low-rank and linear complexity.
Training: Dual encoders require two types of signals for learning: positive signals and negative signals—i.e., <query, item> pairs that should be near each other and those that should be far apart. Lack of either signal can lead to model collapse, where the model outputs a single embedding in the presence of only positive forces. When both signals are difficult to collect, losses are modified to generate negative samples from the same batch (in-batch negatives). There are multiple ways to train a dual encoder, and this remains an active area of research. Most commonly used methods and losses can be found here.
L2 Normalization: L2 normalization is generally applied to the generated embeddings because after normalization, cosine similarity becomes a linear function of Euclidean distance, making both similarity functions follow euclidean metric constraints. One use case where L2 normalization might not be required is when training a model to capture item popularity. If an item x is popular, it can have higher magnitude, leading to more queries having higher inner products with this item. This also occurs when training has popularity bias and embeddings of certain items are updated more frequently.
Limitations:
Dual encoders are generally used for recall due to information loss in their representation
They cannot learn high-rank and non-linear information, limiting their use for high-precision use cases. For example, a movie like “It’s a Wonderful Life” should match queries like “1940s movie,” “Christmas movies,” and “hope movies.” Due to limited representation capabilities, the model would need to position query embeddings close to each other to keep them near the item. Bi-encoders fail to work well for multi-faceted <query, item> interactions.
Cross Encoder
Unlike dual encoders which generate separate embeddings for each query and item pair, cross encoders consume both query and item information in a single inference to generate a final score. This score captures the task results of the <query, item> pair. Cross encoders allow for complex interaction between query and item pairs, enabling more precise results.
Cross encoders learn high-rank information that captures complexities and precision but cannot be efficiently used for inference across a large corpus. Cross encoders don’t allow for quick retrieval of items that best match the query. They are primarily used at ranking layers once items are retrieved using dual encoders. For a list of items retrieved for a given query, cross encoders generate scores for each item. These scores are used to reorder the retrieved items based on task relevance.
Limitations: While cross encoders excel at high-precision tasks, they are computationally intensive and cannot be implemented at large scale. Retrieval of items cannot be performed efficiently
ColBERT: ColBERT optimizes several drawbacks of both cross encoders and bi-encoders by creating a middle ground for interaction:
In cross encoders, query and items interact from the beginning. In dual encoders, they interact only at the very end. ColBERT allows items and queries to initially run independently for a few layers and then enables complex, non-linear interaction at terminal layers.
For a given item corpus, it precomputes token-level embeddings and stores them optimally. During query time, it generates “query token-level embeddings” and computes late interaction scores between these and “item token-level embeddings”
Reduced computation and latency for each <query, item> pair during query time due to precomputation of item token-level embeddings. Allows for more complex interaction between query and item pairs compared to dual encoders
Uses nearest neighbor search for each query token embedding across all item token embeddings to build a set of items for late interaction computation using the MaxSim operator $$ \text{score}(Q, D) = \sum_{i=1}^{m} \max_{j=1}^{n} \left( \mathbf{q}_i^\top \mathbf{d}_j \right) $$ – Q = [q₁, q₂, …, qₘ] are the token-level embeddings of the query – D = [d₁, d₂, …, dₙ] are the token-level embeddings of the document – qᵢ · dⱼ (the dot product between qᵢ and dⱼ) represents the similarity between the i-th query token and the j-th document token – This retrieval approach has limitations as there could be items in the corpus with lower qᵢ · dⱼ for a given query token q_i but potentially higher overall scores across all query tokens
Recent Trends
Generative Retrieval: Generative retrieval is a method where Large Language Models (LLMs) are trained to directly generate items (documents, passages, or identifiers) rather than retrieving them from an index.
Effectively encoding items as sets of tokens is an active area of research. This encoding is necessary for item updates and efficient generation of multiple items.
Multiple items are generated either through sampling techniques (temperature adjustment, top-K, top-P) or by formulating output as a sequence of tokens.
This approach can be computationally expensive, especially when generating large lists of items.
Generative retrieval can directly produce high-quality items, potentially breaking the traditional information retrieval pipeline of retrieval followed by ranking.
Mixture of Logits generates sets of embeddings from both query and item towers. The final similarity between query and items is calculated by applying gated adaptive weights over the low-rank inner products of the query and item embeddings. This approach solves the expressiveness limitation of the standard inner product typically used in dual encoders. While similar to ColBERT, it differs in several important aspects:
Embedding Generation: The embeddings are not token-level representations. Instead, they are generated from the encoder and can be heterogeneous, potentially coming directly from other parallel systems.
Interaction Mechanism: Unlike ColBERT, which uses simple max operations on dot products, Mixture of Logits calculates the final score as a function of inner products and gated weights that adapt for each <query, item> pair. In the original paper, the authors prove that Mixture of Logits functions as a universal approximator of similarity functions—capable of learning any high-rank matrix by decomposing it into a mixture of logits of low-rank matrices.
Loss Function Design: The authors developed a supplemental loss function that ensures each embedding output is appropriately utilized. For a given <query, item> pair, this function encourages the gate function to concentrate on a few key inner products.
Retrieval Efficiency: The paper proposes specific heuristics for efficient document retrieval using query embeddings, leveraging existing nearest neighbor algorithms.
Conclusion
The landscape of information retrieval has evolved dramatically with the introduction of neural architectures that offer varying trade-offs between computational efficiency and retrieval quality. From traditional dual encoders to advanced architectures like cross encoders, ColBERT, and Mixture of Logits, each approach presents unique advantages and limitations.
Autoencoders establish the foundational principle of information bottlenecks, allowing models to learn compressed yet meaningful representations. Dual encoders provide efficient but sometimes limited representations, while cross encoders offer high precision at the cost of computational intensity. ColBERT strikes a balance with its late interaction paradigm, and Mixture of Logits further enhances expressiveness through adaptive weighting mechanisms.
The emergence of generative retrieval represents perhaps the most radical departure from traditional methods, bypassing the conventional retrieve-then-rank pipeline by directly generating relevant items. This approach, while computationally demanding, points toward a future where the boundaries between retrieval, ranking, and generation become increasingly blurred.
As these architectures continue to evolve, the field moves toward systems that can balance computational efficiency with the rich, contextual understanding necessary for truly effective information retrieval. The ongoing research in this domain promises to deliver increasingly sophisticated solutions that can handle the complexity and scale of modern information needs while maintaining practical deployment requirements.