The purpose of this series is to summarize the latest breakthroughs, problems, and solutions in the field of natural language processing and language understanding.
Language Model
In layman term, language model is probability distribution over words or word sequences, in a particular given context.
- LM is trained to predict if a certain words or sequences is “valid”, in the given context
- It mines the language structure, grammar, schemas and in general rules of how people speak (or more specifically, how people write)
- a tool for compressing information from abundant corpus of unstructured text. This helps the model to be used in an out-of-sample context
The abstract understanding of natural language can be useful in multiple tasks
- stemming and lemmatization: reduces the words to its root form and POS tagging of the words helps in resolving the word meaning and context. This helps in better accuracy of stemming and lemmatization
- extractive and abstractive summarisation
- machine translation
- sentiment classification
- indirect usecases: speech recognition, OCR, handwriting recognition, question answering
Approaches to Language Models
- Context Unaware: One hot encoding, TF-IDF
- Probabilistic Method: Bigrams, n-gram models
The drawback to this approach is that it fails to capture the underlying meaning of the sentence or the “context”. Complicated texts have a very decisive meaning to communicate. This is something which is hard to model even when n (-gram) is 15 or 20. This is “context problem”

Additionally, n increases, the number of permutations of the words explodes, which makes it harder to scale. Also, most of the permutation never occur in the text. This creates a “sparsity problem”
- Neural Language Model: ease the sparsity problem by the way it encodes input: “embeddings”. Embedding is a fixed arbitrary size vector representing a word. It is trained to fulfill a task, related to predicting next word or next phrases.
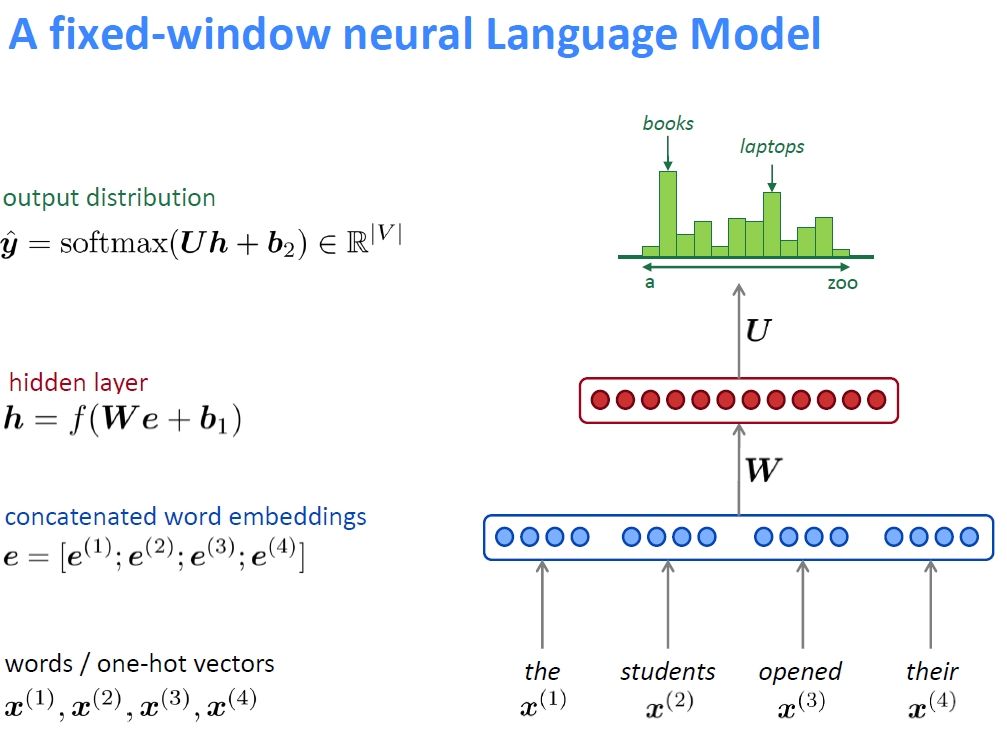
- The above architecture solves for the sparsity problem but the context problem remains
- The model above is continuous bag of words (CBOW) word2vec model.
- the inputs are n words before and/or m words after the word, while the task is to predict the word. For example for sentence “Ghostbusters is a 1984 American supernatural comedy film directed and produced by Ivan Reitman and written by Dan Aykroyd and Harold Ramis.” one such training sample for n=2 and m=1 will be “Ghostbusters is 1984” and output is ‘a’.
- RNNs: Improvement of over CBOW is to use RNNs like LSTM or GRU to capture long term context to predict the next word.
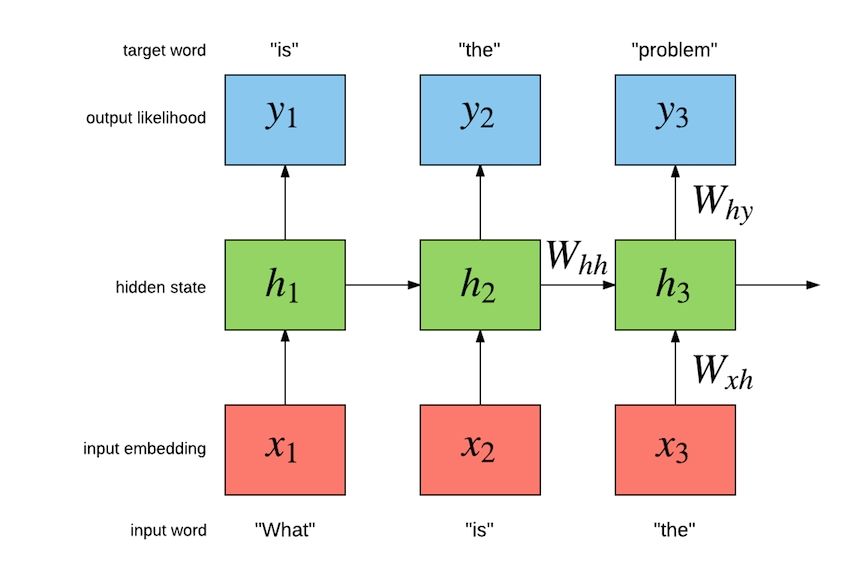
- Transformers: The drawback of RNNs is their inability to parallelize the execution, because of the its sequential execution. This leads to soaring of training times for long sequences. The transformer architecture solves this problem by performing computations in parallel and employing “attention”. The attention mechanism helps to focus specific words in the sentences to generate the prediction of the next word. This help the model in capturing long term dependencies by helping it focus on particular words for generating outputs. Additionally the GPT-3 (a transformer based model) was trained on the largest corpus a model has ever seen: “Common Crawl”. This is partly because of the semi supervised training approach – a text can be used as a training example with some words omitted.
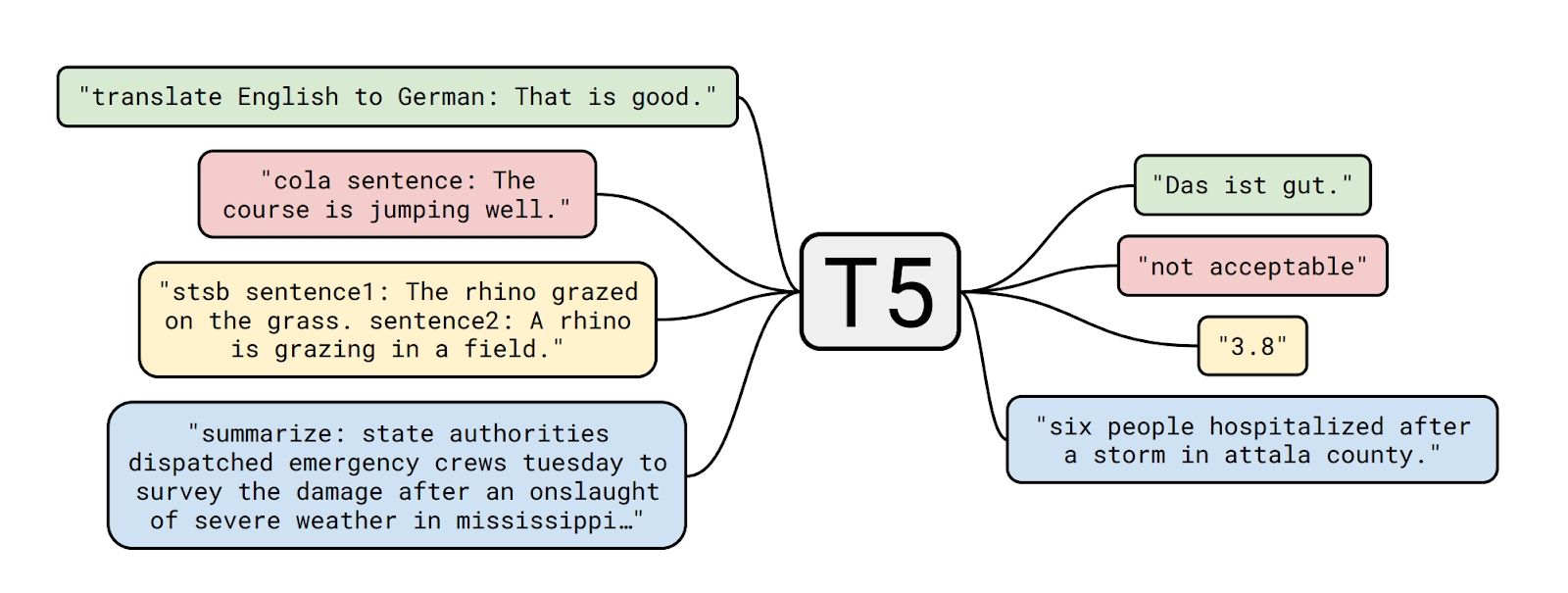
- T5 model from Google: This model is trained for multiple tasks compared the previous model which were trained on to predict next word or missing words. Because of this strategy of training this T5 model can be directly used for common problems like POS tagging, machine translation, etc.
References
- A beginner’s guide to language models https://towardsdatascience.com/the-beginners-guide-to-language-models-aa47165b57f9